Just been reading a nice paper from Thomas Ward, @OvertonC and co on IFR estimation which seems to do a really nice job: The real-time infection hospitalisation and fatality risk across the COVID-19 pandemic in England | Nature Communications
Driven by this thread: @michaelplanknz.bsky.social on Bluesky
The Code Problem
From the methods etc, it looks like a good job, and obviously, they usually do good work. However, when I started to properly engage, I got to: “The model code can be made available on request to DataAccess@ukhsa.gov.uk.”
(I have emailed but usually these processes give you an endless run around just due to the nature of what they are and the more serious data they are usually trying to keep confidential).
Turns out reviewers weren’t given code either. From the review response: “There was no code to review. The data are held in safe havens for another researcher would have to apply to run the analyses in these safe havens also. Making the Stan code available for other researchers would probably be a good idea but there are sufficient…”
So no one has seen the code but this reviewer things that the methods are “sufficient”?
Most of the time if I hit this in a paper, I stop reading it and make it a point of principle to avoid citing it or recommending it to others.
Had an exchange with Thomas House (@tah-sci.com) who pointed out the UKHSA group is under “correctly very strict data security.” Fair for data but Stan code is not@tah-sci.comtah-sci.comdata. UKHSA usually shares code on GitHub so not sure why not here?
Looking for Alternatives
In this instance, I went looking for other sources for that discussion and found: Dynamics of SARS-CoV-2 infection hospitalisation and infection fatality ratios over 23 months in England
Which is similar but limited to REACT. Not clear why the Ward paper doesn’t cite this, given the overlap? The reviewer reports said they didn’t find any papers with overlap which seems odd. Maybe its not as close as I think from skimming.
Digging into the Methods
From skimming both, I think I marginally prefer the Ward paper as I don’t love the REACT spline approach more generally, and the Ward paper looks to do a nice data integration job. UKHSA usually have all the best data as well so I would also be biased in that direction for that reason.
But trying to understand what’s actually going on is hard. Reviewer 2 asked for a methods diagram - the response says they added one but I can’t find it in the manuscript. Went to check the SI (https://static-content.springer.com/esm/art%3A10.1038%2Fs41467-024-47199-3/MediaObjects/41467_2024_47199_MOESM1_ESM.pdf) and the methods overview diagram is Figure 48! It’s flagged at the head of the methods (“For each study (Supplementary Fig. 48) we describe the modelling to calculate…”), but how many people are going on the journey needed to find it?
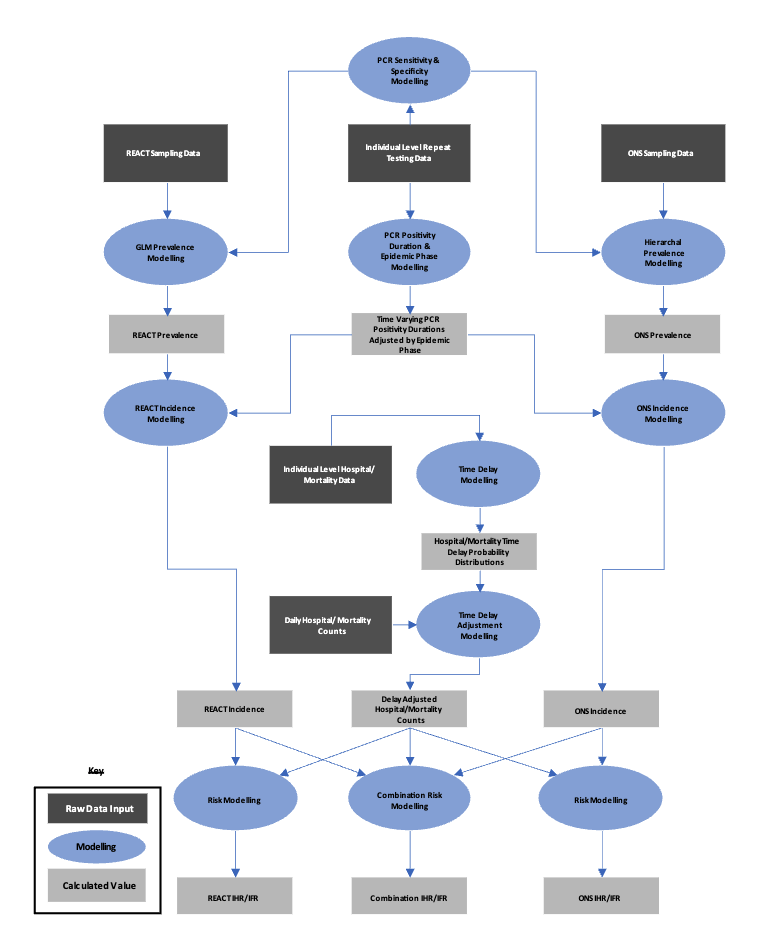
This got me looking at the SI in more detail. No more methods here just lots of figures (I think a much less text-heavy bit of maths would help me). The credible intervals on PCR positive in SI Fig 1 are very, very tight - wonder what’s going on there. Looking back at the methods, I am none the wiser, and I don’t think I have the tools from the text to find out.
I like the main figure and SI results, where they show the combined and ONS vs REACT estimates. These could be useful for understanding data integration issues/conflict but I don’t find this in the paper being discussed (missing it?).
(It’s a Monday, so maybe I’m just grumpy)
No standard Bayesian workflow stuff about prior or posterior predictive checks that I can see. Nothing about data integration issues or approximation issues from passing data between models. So from that and no code hard to know if the model works imo.
I think as a field we do a really, really bad job at this (i.e. this paper is doing quite a good job relatively). We don’t really have standards or guidelines and reviewers/journals usually don’t really care. For this reason currently writing a bit of a checklist paper for data integration that aims to try and help standardise these things
Thoughts from diving in
My main concern would be about the delay from infection to testing positive being onset and nothing being done about this or it being explored anywhere. None of the reviews flag this that I can see - the REACT paper also does this I think which isn’t great for these kind of papers.
This statement seems wrong no matter how I read it: “assumption that time of symptom onset approximates the time at which the case becomes positive. While it would be possible to not make this assumption and use an interval censoring model… due to the size of the intervals relative to the delay, the uncertainty on any estimates produced using this approach would be too large and would consequently degrade results.”
If this uncertainty exists, it means your time-varying parameters are way too precise i.e. can’t be resolved. “Degrade results” equals make realistic? I don’t see any reviewer comments about this so perhaps I am misunderstanding something
We do start from infection time here and it seems fine: Combined analyses of within-host SARS-CoV-2 viral kinetics and information on past exposures to the virus in a human cohort identifies intrinsic differences of Omicron and Delta variants
This all means the estimates are now time-varying IFR by onset time I think (“we shift the testing dates to symptom onset date rather than infection date, since we have more reliable data on the delay distributions post symptom onset date”) which I think isn’t clear in the limitations and introduces some hard to fully understand biases.
Note: I have problems here as well as we use a rubbish prior for our infection times. I think all these models need to have some kind of epidemic growth rate model under the hood informing these priors.
Equation 16, where incidence is backed out from prevalence by dividing by expected duration positive, the length of the round and the pop size worries me. Looks like back-sampling of infection times which, as we found to our cost is not the right way to do things: Practical considerations for measuring the effective reproductive number, Rt
I think this also means each round is independent from other rounds which again seems like a problematic assumption that lead to some knock on impacts in the results (I think they try and get around this in a later part of their pipeline by smoothing over the IFR estimates?).
I think you want a forward model of I here, which who knows might actually be whats in the code (i.e. not above but in a different part of the submodel but same difference).
The discussion says the issue is that the growth rate within a round is ignored - how much this matters depends on the round length. I would worry a lot about this if a round was more than say a week and I was going to use the time-varying parameters at rates of lower than say a month. As a modeller, I would find this hard to be chill about myself regardless of the intervals.
I will probably wait for code until I look at this more as from the methods narrative, I am struggling to fully get to grips with what they did and the assumptions that were made and when those matter. This probably isn’t a great sign as despite just generally vibing my way through work I have written papers about some quite similar models so I would imagine that if I am not following, only probably a fairly narrow group would do so without engaging more than I can on a Monday full of deadlines.
Different Standards?
So I would probably use the REACT results for my work. If this wasn’t from a Public health agency, I wouldn’t even consider using the estimates due to the lack of code and would engage with it in only a very limited way.
What would others do?
This got me thinking more generally about the standards I hold public health teams to vs academics and it’s definitely different. I am more willing to allow less code, less likely to challenge method issues etc.
I would also usually consider Nature Communications as basically predatory and so be less likely to engage again for that reason (not a fan we are spending public money on these publishing charges folks - I hope you get them waived).
I wonder why I think this though as often the public health teams will have more senior people writing papers (seems to be the case at the moment which imo is a good thing but also means standards should be higher?) and more access to the data so fewer needs to make approximations. It’s also harder to critically assess as often they are making decisions based on context others don’t have i.e. that is internal. Again I usually give this a free pass.
Part of this is lack of leverage I guess but I also do it when reviewing when I obviously do have leverage (though leverage at peer review is stupid just like the rest of the process).
On the flip side, I would far rather methods and estimates being used were public domain so I can have a whine (like this) rather than all just being kept internal and never really checked (like some other public health agencies that come to mind) so maybe having different standards is okay? Or perhaps we need a different way of sharing things more generally, that is a bit less of a pointless formal dance that wastes everyone’s time? I generally think this for all academic style work - we should just have preprints and then people post reviews and there can be external editor filtering if people wish.
Something I would like to see if agencies engage in more review with a feedback loop into their work - this could be a really neat role for the HPRUs. The problem with this is independence as usually, unless you are a relentless maverick (![]() ) bent on not having any career success (
) bent on not having any career success (![]() ), biting the hand that feeds is not usually a good idea.
), biting the hand that feeds is not usually a good idea.
Why? Well we need impact right! This means all the different parts of agencies end up with academic friends (not immune from this) and get siloed feedback. This is also obviously true in academic networks so perhaps a wider problem.
Moving Forward
To be clear, this is a really good piece of work and the above are niggles. Without code though, it’s hard to properly evaluate or build on. I’m pretty sure that the lack of code is probably outside the authors control.
Wonder if someone from this team would like to come and give a retrospective on this work at an epinowcast seminar? I would love to understand the modelling choices as well as the background around reporting better and I think others would too.
What do others think? Very interested to hear from Public health colleagues, especially. Is this all just Monday Sam?